Software: SimX - Nadelantrieb - Probabilistik - Second-Order: Unterschied zwischen den Versionen
| (79 dazwischenliegende Versionen von 3 Benutzern werden nicht angezeigt) | |||
| Zeile 1: | Zeile 1: | ||
[[Software:_SimX_-_Nadelantrieb_-_Probabilistische_Simulation| | [[Software:_SimX_-_Nadelantrieb_-_Probabilistische_Simulation|↑]] <div align="center"> [[Software:_SimX_-_Nadelantrieb_-_Probabilistik_-_Moment-Methoden|←]] [[Software:_SimX_-_Nadelantrieb_-_Probabilistische_Simulation|→]] </div> | ||
<div align="center">'''Second Order (Experimente)'''</div> | <div align="center">'''Second Order (Experimente)'''</div> | ||
== Versuchsplanung == | |||
Im Prinzip stehen bei der Nutzung der Moment-Methode die gleichen Analyse-Werkzeuge zur Verfügung, wie bei den Sample-Verfahren. Nur im Detail existieren Unterschiede in Hinblick auf die Verfügbarkeit und Genauigkeit einzelner statistischer Kenngrößen. | Im Prinzip stehen bei der Nutzung der Moment-Methode die gleichen Analyse-Werkzeuge zur Verfügung, wie bei den Sample-Verfahren. Nur im Detail existieren Unterschiede in Hinblick auf die Verfügbarkeit und Genauigkeit einzelner statistischer Kenngrößen. | ||
= | * Deshalb können wir mit dem vorhandenem Experiment-Workflow und den bereits konfigurierten Entwurfsparametern (Streuungen) und Restriktionen beginnen: | ||
[[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_versuchsplanung_second-order.gif| | <div align="center">[[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_versuchsplanung_second-order.gif|.]]</div> | ||
Wir nutzen die Moment-Methode mit einer Taylorreihe 2. Ordnung zur Approximation und berücksichtigen Interaktionen zwischen den Streugrößen: | * Umschalten müssen wir nur das Verfahren der Versuchsplanung auf die Moment-Methode. | ||
* Aus unseren Erfahrungen mit der Sampling-Methode wissen wir bereits, dass die Zusammenhänge zwischen den Streu- und Ausgangsgrößen | |||
Wir nutzen die Moment-Methode mit einer Taylorreihe 2. Ordnung zur Approximation und berücksichtigen die Interaktionen zwischen den Streugrößen: | |||
* Ob Taylorreihen 2. Ordnung die tatsächlichen Zusammenhänge zwischen Streu- und Ausgangsgrößen hinreichend widerspiegeln, kann man nur im Vergleich mit Ersatzfunktionen höherer Ordnung erkennen. | |||
* Aus unseren Erfahrungen mit der Sampling-Methode wissen wir bereits, dass die Zusammenhänge zwischen den Streu- und Ausgangsgrößen teilweise nichtlinear sind. Das konnte man in den Schnittdiagrammen mit Polynomen 3. Ordnung deutlich erkennen: | |||
<div align="center">[[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_rsm-schnittdiagramm.gif|.]]</div> | |||
* Bei der ''Moment-Methode'' können höchsten Taylorreihen 2. Ordnung als Approximationsfunktion benutzt werden. Über Taylorreihen höherer Ordnung lassen sich die Verteilungen der Ausgangsgrößen durch die statistischen Momente mathematisch nicht mehr genau approximieren, weil sie (die Verteilungen) auch die Momente höherer Ordnungen enthalten müssten. | * Bei der ''Moment-Methode'' können höchsten Taylorreihen 2. Ordnung als Approximationsfunktion benutzt werden. Über Taylorreihen höherer Ordnung lassen sich die Verteilungen der Ausgangsgrößen durch die statistischen Momente mathematisch nicht mehr genau approximieren, weil sie (die Verteilungen) auch die Momente höherer Ordnungen enthalten müssten. | ||
== Visualisierung und Interpretation == | == Visualisierung und Interpretation == | ||
[[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_- | |||
Die reale "Stichprobe" beschränkt sich bei der Moment-Methode auf das kombinatorische Abtasten der Toleranzgrenzen bzw. der Toleranzmitten aller Streugrößen: | |||
* Zuerst erfolgt eine Simulation des Nennwertes (zentrale Stützstelle im Streubereich), deren Daten man über die Nennwert-Tabelle abrufen kann. Da wir keine Optimierung, sondern nur eine Simulation durchführen, ist die eine Nennwert-Simulation gleichzeitig der Bestwert, welcher eine übersichtlichere Darstellung bietet:<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_Second-Order_Nennwert.gif|.]] </div> | |||
* '''''Hinweise'':''' | |||
*# Auch bei der Sample-Methode erfolgte zuerst eine Nennwert-Simulation. | |||
*# Dieser "Nennwert" entspricht im Beispiel nicht exakt dem "Bestwert" der Nennwert-Optimierung. Ursache ist die unterschiedliche Spulentemperatur für beide Simulationen (25°C bzw. 90°C)! | |||
* Eine komplette Übersicht über die restlichen Modellberechnungen der Stichprobe erhält man in "Echtzeit" mittels der DOE-Tabelle:<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_Second-Order_DOE-Tabelle.gif|.]] </div>[[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_Second-Order_Anthill-Plot.gif|right]] | |||
* Die berechneten Stützstellen der DOE-Tabelle kann man (ebenfalls in Echtzeit) in Anthil-Plots darstellen. Je nach Belegung der Achsen erkennt man darin recht anschaulich das Abtastungsschema innerhalb des Streubereiches der Parameter. | |||
'''''Wichtig'':''' | |||
* Die Taylorreihen (als Ersatzfunktionen) der Moment-Methode und damit die Probabilistik können nur berechnet werden, wenn alle Stützstellen erfolgreich simuliert wurden ('''Status=Ok''')! Bei den Sample-Methoden verringern "erfolglose" Simulationen nur die Größe der nutzbaren Stichprobe. | |||
*# Die Diode als numerisch kritisches Modell-Element kann hier zu Problemen führen, indem einzelne Simulationsläufe mit "Status=Failed" enden. | |||
*# Bekommt man dieses Problem mit der Diode nicht durch eine verbesserte Konfiguration der numerischen Integration in den Griff, muss man die Diode durch eine direkte Verbindung ersetzen!. Es entsteht dadurch jedoch ein geringer Parallelstrom zur Spule im eingeschalteten Zustand. | |||
* Bei der Nutzung der Moment-Methode stehen Histogramme und Korrelationen nicht zur Verfügung (im Analyse-Menü inaktiv). | * Bei der Nutzung der Moment-Methode stehen Histogramme und Korrelationen nicht zur Verfügung (im Analyse-Menü inaktiv). | ||
=== Streuungen === | === Streuungen === | ||
'''''Analyse > Probabilistik > Verteilungsdichten > Entwurfsparameter > Streuungen''''' zeigt für die gewählten Streuungen (ergänzt um die Hilfsrestriktionsgröße "'''kFeder'''") die "perfekten" [https://de.wikipedia.org/wiki/Verteilungsdichte '''Verteilungsdichtefunktionen''']:<div align="center">[[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_verteilungsdichte_toleranzen.gif|.]]</div> | |||
<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_- | * Die Fläche unter einer Verteilungsdichte-Funktion besitzt immer den Wert 1. | ||
* Die Verteilungsdichte-Funktionen sind die Ableitungen der zugehörigen Verteilungsfunktionen nach ihrer Streugröße. Das erkennt man besonders deutlicher am Beispiel der gleichverteilten Spulentemperaturen und Papierdicken:<div align="center">[[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_verteilung_toleranzen.gif|.]]</div> | |||
=== Restriktionsgrößen === | |||
'''''Beachte'':''' Für die "Hilfsgrößen" im Workflow (Ausgangsgrößen und Transfervariablen) werden keine Ersatzfunktionen approximiert. Deshalb erfolgt für diese Hilfsgrößen auch keine Probabilistik-Berechnung. | |||
Bei den Restriktionsgrößen interessiert vor allem, in welchem Maße infolge der Streuungen unzulässige Werte auftreten: | Die Verteilungsdichten der Ergebnisgrößen werden auf Grundlage der approximierten Taylorreihen 2. Ordnung und der darüber transformierten statistischen Momente der streuenden Eingangsgrößen für alle Restriktionen/Gütekriterien des Workflows berechnet: | ||
* Bei den Restriktionsgrößen interessiert vor allem, in welchem Maße infolge der Streuungen unzulässige Werte auftreten: | |||
<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_verteilungsdichte_restriktionen.gif| ]] </div> | <div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_verteilungsdichte_restriktionen.gif| ]] </div> | ||
* Im Beispiel wurden bei der Nennwert-Optimierung die maximale Abschaltspannung und der Maximalstrom ausgereizt. Das äußert sich in einer Teilversagenswahrscheinlichkeit von | * Im Beispiel wurden bei der Nennwert-Optimierung die maximale Abschaltspannung und der Maximalstrom ausgereizt. Das äußert sich in einer Teilversagenswahrscheinlichkeit von mehr als 50% für beide Restriktionsgrößen. | ||
* Der Grenzwert von | * Der Grenzwert von 40 K für die Drahterwärmung wird "praktisch" kaum überschritten. | ||
* '''Hinweis:''' Leider kann man anhand der dargestellten Grenzwerte nur näherungsweise die tatsächlichen Grenzen der Streubereiche abschätzen. OptiY schneidet Werte der Dichtefunktion ab, die kleiner als 1/100 ihres Maximalwertes sind. | * '''Hinweis:''' Leider kann man anhand der dargestellten Grenzwerte nur näherungsweise die tatsächlichen Grenzen der Streubereiche abschätzen. OptiY schneidet Werte der Dichtefunktion ab, die kleiner als 1/100 ihres Maximalwertes sind. | ||
| Zeile 59: | Zeile 55: | ||
Die Teilversagenswahrscheinlichkeiten der einzelnen Restriktionen '''F<sub>i</sub>''' können mit der Moment-Methode sehr genau berechnet werden, weil die Verteilungsdichten der Restriktionen bekannt sind. Aber die gesamte Systemversagenswahrscheinlichkeit '''F''' kann man damit nicht analytisch ermitteln: | Die Teilversagenswahrscheinlichkeiten der einzelnen Restriktionen '''F<sub>i</sub>''' können mit der Moment-Methode sehr genau berechnet werden, weil die Verteilungsdichten der Restriktionen bekannt sind. Aber die gesamte Systemversagenswahrscheinlichkeit '''F''' kann man damit nicht analytisch ermitteln: | ||
* Es wird eine Hilfsgröße '''F''' berechnet, die sich aus den Teilversagenswahrscheinlichkeiten '''F<sub>i</sub>''' mit den Gewichtsfaktoren '''w<sub>i</sub>''' der einzelnen Restriktionen summiert:<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_gesamtversagen.gif| ]] </div> | * Es wird eine Hilfsgröße '''F''' berechnet, die sich aus den Teilversagenswahrscheinlichkeiten '''F<sub>i</sub>''' mit den Gewichtsfaktoren '''w<sub>i</sub>''' der einzelnen Restriktionen summiert: | ||
<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_gesamtversagen.gif|.]] </div> | |||
* Diese Hilfsgröße '''F''' wird als Maß für das Versagen im OptiY-Explorer als Bestandteil der Gütekriterien aufgelistet. Den Wert kann man sich z.B. in einem " | * Diese Hilfsgröße '''F''' wird als Maß für das Versagen im OptiY-Explorer als Bestandteil der Gütekriterien aufgelistet. Den Wert kann man sich z.B. in einem "Nennwert-Verlauf"-Fenster anzeigen lassen: | ||
<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_versagen_in_explorer.gif|.]] [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_versagensmasz_moment-methode.gif|.]] </div> | |||
* Bei einem ''Versagen > 1'' wird spätestens klar, dass dieser Wert '''F''' nur ein "Maß" für die Gesamtversagenswahrscheinlichkeit ist: | * Bei einem ''Versagen > 1'' wird spätestens klar, dass dieser Wert '''F''' nur ein "Maß" für die Gesamtversagenswahrscheinlichkeit ist: | ||
** Damit erhält man für die Minimierung der Versagenswahrscheinlichkeit mittels numerischer Optimierung ein stetiges und eindeutiges Maß für die vergleichende Bewertung von Lösungen. | ** Damit erhält man für die Minimierung der Versagenswahrscheinlichkeit mittels numerischer Optimierung ein stetiges und eindeutiges Maß für die vergleichende Bewertung von Lösungen. | ||
| Zeile 73: | Zeile 70: | ||
'''Lokale Sensitivität''' | '''Lokale Sensitivität''' | ||
Auch für die Moment-Methode werden die lokalen Sensitivitäten als | Auch für die Moment-Methode werden die lokalen Sensitivitäten als Schnittdiagramme bereitgestellt ('''''Analyse > Antwortflächen > 1D Diagramm'''''): | ||
* Die Antwortflächen werden in diesem Falle durch die approximierten Taylorreihen 2. Ordnung gebildet. | * Die Antwortflächen werden in diesem Falle durch die approximierten Taylorreihen 2. Ordnung gebildet. | ||
* | * Im Unterschied zur Sample-Methode erfolgt die Gewinnung dieser Ersatzfunktion auf Grundlage einer systematischen Abtastung des Modells an einer minimalen Anzahl definierter Stützstellen: | ||
<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_schnittdiagramm_moment-methode.gif]] </div> | <div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_schnittdiagramm_moment-methode.gif]] </div> | ||
* '''''Hinweis:''''' Anhand der Krümmungen der Schnittfunktionen kann man schlussfolgern, dass die Wahl einer linearen Ersatzfunktion (''First Order'') wahrscheinlich eine unzulässige Vereinfachung darstellen würde. | * '''''Hinweis:''''' Anhand der Krümmungen der Schnittfunktionen insbesondere bei großen ΔY-Werten kann man schlussfolgern, dass die Wahl einer linearen Ersatzfunktion (''First Order'') wahrscheinlich eine unzulässige Vereinfachung darstellen würde. | ||
'''Globale Sensitivitäten''' | '''Globale Sensitivitäten''' | ||
| Zeile 90: | Zeile 87: | ||
* Damit entfallen die Modellberechnungen für die Gewinnung der Interaktionsinformationen. | * Damit entfallen die Modellberechnungen für die Gewinnung der Interaktionsinformationen. | ||
* Für 5 Streugrößen reduziert sich damit der Berechnungsaufwand von ''2n²+1=51'' auf ''2n+1=11'' auf fast ein Fünftel! | * Für 5 Streugrößen reduziert sich damit der Berechnungsaufwand von ''2n²+1=51'' auf ''2n+1=11'' auf fast ein Fünftel! | ||
Im Beispiel weichen die Werte für Haupt- und Totaleffekte insbesondere für den Maximalstrom und die | Im Beispiel weichen die Werte für einige Haupt- und Totaleffekte insbesondere für den Maximalstrom und die Erwärmung merklich voneinander ab. Ob man dabei noch von "ungefähr gleich" sprechen kann, ist schwer zu entscheiden, solange man die Auswirkungen auf die Genauigkeit der probabilistischen Simulation nicht kennt: | ||
* Man sollte in diesem Fall die Ergebnisse der probabilistischen Simulation mit und ohne Berücksichtigung der Interaktionen vergleichen. | * Man sollte in diesem Fall die Ergebnisse der probabilistischen Simulation mit und ohne Berücksichtigung der Interaktionen vergleichen. | ||
* Nach erneuter Simulation (''Interaktion=false'') werden in den | * Nach erneuter Simulation (''Interaktion=false'') werden in den Sensitivitäts-Charts nur die Haupteffekte angezeigt:<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_sensitivity-chart_haupteffekte.gif]] </div> | ||
<div align="center"> [[Bild:Software_SimX_-_Nadelantrieb_-_Probabilistische_Simulation_-_sensitivity-chart_haupteffekte.gif]] </div> | Kann man nach gründlicher Analyse der globalen Sensitivitäten z.B. 2 Streuungen vernachlässigen und aus dem Experiment-Workflow entfernen, so ergibt das eine weitere Verringerung des Berechnungsaufwandes auf ''2n+1=7'': | ||
Kann man nach gründlicher Analyse der globalen | |||
* Insbesondere in Vorbereitung einer geplanten probabilistischen Optimierung ist eine tiefgründige Analyse der Modelleigenschaften unbedingt erforderlich. | * Insbesondere in Vorbereitung einer geplanten probabilistischen Optimierung ist eine tiefgründige Analyse der Modelleigenschaften unbedingt erforderlich. | ||
* Ausgehend von genaueren, aber auch zeitaufwändigeren Simulationen sollte man die "Stichproben-Simulation" soweit es geht "abrüsten", ohne dabei wesentlich an Genauigkeit einzubüßen. | * Ausgehend von genaueren, aber auch zeitaufwändigeren Simulationen sollte man die "Stichproben-Simulation" soweit es geht "abrüsten", ohne dabei wesentlich an Genauigkeit einzubüßen. | ||
| Zeile 100: | Zeile 96: | ||
== Experiment-Ergebnisse == | == Experiment-Ergebnisse == | ||
Für das eigene Nennwert-Optimum sind von den Teilnehmern der Lehrveranstaltung auf Grundlage der Simulation mittels Moment-Methode folgende Fragen als Bestandteil der einzusendenden Lösung zu beantworten: | |||
* Welche drei streuungsbehafteten Parameter besitzen den größten Einfluss auf das Verhalten des Prägenadel-Antriebs? | * '''Welche drei streuungsbehafteten Parameter''' besitzen den größten Einfluss auf das Verhalten des Prägenadel-Antriebs? Die Entscheidung ist zu begründen! | ||
* | * '''Wie ändern sich die Total-Effekte''' (vorher / nachher) von Feder-Streuung und Papier-Streuung auf die relevanten Bewertungsgrößen, wenn man die beiden Parameter-Streuungen mit dem geringsten Effekt vernachlässigt? | ||
# | * '''Wirkung der Interaktionen''' → Zusätzlich sind für die auf 3 Streuungen reduzierte probabilistische Simulation vergleichend (vorher / nachher) folgende Werte der relevanten Bewertungsgrößen aufzulisten, wenn man die Interaktionen berücksichtigt bzw. vernachlässigt: | ||
# | *# '''Mittelwerte''' | ||
* Wie groß ist | *# '''Maximal- und Minimalwerte''' anhand der Verteilungsdichte-Diagramme | ||
*# '''Teilversagenswahrscheinlichkeiten''' | |||
* '''Ausschussquote''': Wie groß ist für den Nennwert-optimierten Antrieb die "Gesamtversagenswahrscheinlichkeit [in %]" (Unter Berücksichtigung der Ergebnisse aus der Sample-Methode und Begründung der Wahl)? | |||
'''''Hinweise'':''' | |||
* Im Unterschied zur Sample-Methode haben die Einstellungen im virtuellen Entwurf keinerlei Einfluss auf die Ergebnisse der probabilistischen Simulation. Der virtuelle Entwurf wird in der Moment-Methode komplett ersetzt durch die analytische Berechnung der statistischen Momente der Ergebnis-Streuungen. | |||
* Wir setzen vor den erforderlichen Experimenten in der realen Stichprobe der Versuchsplanung die Toleranz der zu vernachlässigenden Streuungen auf einen sehr kleinen Wert (auf '''1/1000''' der Original-Toleranz → für problemlose Rückänderung). | |||
* Erforderlich ist danach jeweils eine komplette Neuberechnung nach dem Zurücksetzen der letzten Simulationsergebnisse. | |||
<div align="center"> [[Software:_SimX_-_Nadelantrieb_-_Probabilistik_-_Moment-Methoden| | '''Vorbereitung der Lösungseinsendung:''' | ||
* Konfiguration des Experiments ohne reduzierte Streuungen unter Berücksichtigung der Interaktionen und den zugehörigen vollständig berechneten Ergebnissen. | |||
* Der Workflow und alle Analyse-Fenster sind zu minimieren, mit Ausnahme der beiden zuletzt benutzten: | |||
*# '''Verteilungsdichten''' der relevanten Restriktionsgrößen | |||
*# '''Sensitivity Chart''' der relevanten Restriktionen | |||
<div align="center"> [[Software:_SimX_-_Nadelantrieb_-_Probabilistik_-_Moment-Methoden|←]] [[Software:_SimX_-_Nadelantrieb_-_Probabilistische_Simulation|→]] </div> | |||
Aktuelle Version vom 27. Mai 2024, 08:20 Uhr
Versuchsplanung
Im Prinzip stehen bei der Nutzung der Moment-Methode die gleichen Analyse-Werkzeuge zur Verfügung, wie bei den Sample-Verfahren. Nur im Detail existieren Unterschiede in Hinblick auf die Verfügbarkeit und Genauigkeit einzelner statistischer Kenngrößen.
- Deshalb können wir mit dem vorhandenem Experiment-Workflow und den bereits konfigurierten Entwurfsparametern (Streuungen) und Restriktionen beginnen:

- Umschalten müssen wir nur das Verfahren der Versuchsplanung auf die Moment-Methode.
Wir nutzen die Moment-Methode mit einer Taylorreihe 2. Ordnung zur Approximation und berücksichtigen die Interaktionen zwischen den Streugrößen:
- Ob Taylorreihen 2. Ordnung die tatsächlichen Zusammenhänge zwischen Streu- und Ausgangsgrößen hinreichend widerspiegeln, kann man nur im Vergleich mit Ersatzfunktionen höherer Ordnung erkennen.
- Aus unseren Erfahrungen mit der Sampling-Methode wissen wir bereits, dass die Zusammenhänge zwischen den Streu- und Ausgangsgrößen teilweise nichtlinear sind. Das konnte man in den Schnittdiagrammen mit Polynomen 3. Ordnung deutlich erkennen:

- Bei der Moment-Methode können höchsten Taylorreihen 2. Ordnung als Approximationsfunktion benutzt werden. Über Taylorreihen höherer Ordnung lassen sich die Verteilungen der Ausgangsgrößen durch die statistischen Momente mathematisch nicht mehr genau approximieren, weil sie (die Verteilungen) auch die Momente höherer Ordnungen enthalten müssten.
Visualisierung und Interpretation
Die reale "Stichprobe" beschränkt sich bei der Moment-Methode auf das kombinatorische Abtasten der Toleranzgrenzen bzw. der Toleranzmitten aller Streugrößen:
- Zuerst erfolgt eine Simulation des Nennwertes (zentrale Stützstelle im Streubereich), deren Daten man über die Nennwert-Tabelle abrufen kann. Da wir keine Optimierung, sondern nur eine Simulation durchführen, ist die eine Nennwert-Simulation gleichzeitig der Bestwert, welcher eine übersichtlichere Darstellung bietet:
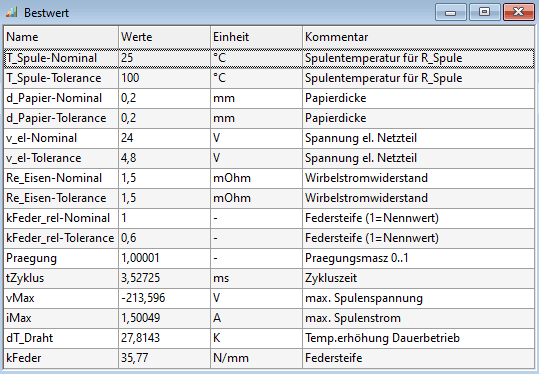
- Hinweise:
- Auch bei der Sample-Methode erfolgte zuerst eine Nennwert-Simulation.
- Dieser "Nennwert" entspricht im Beispiel nicht exakt dem "Bestwert" der Nennwert-Optimierung. Ursache ist die unterschiedliche Spulentemperatur für beide Simulationen (25°C bzw. 90°C)!
- Eine komplette Übersicht über die restlichen Modellberechnungen der Stichprobe erhält man in "Echtzeit" mittels der DOE-Tabelle:
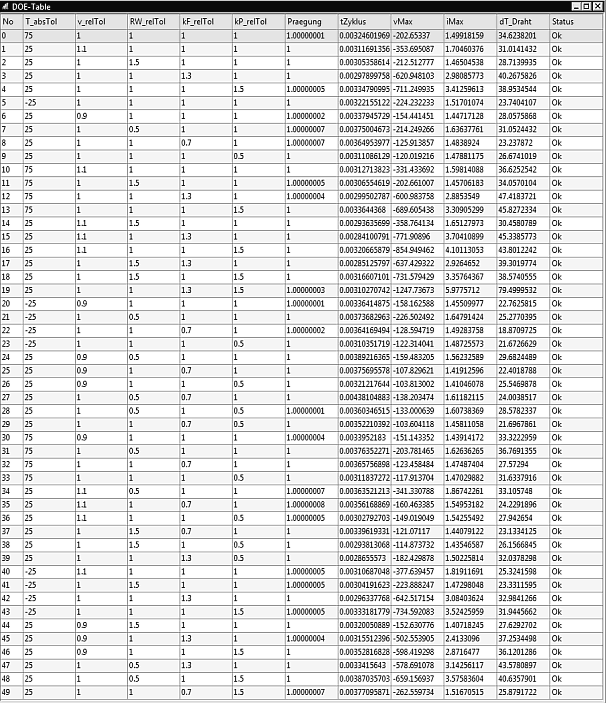
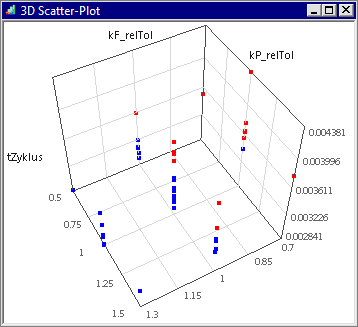
- Die berechneten Stützstellen der DOE-Tabelle kann man (ebenfalls in Echtzeit) in Anthil-Plots darstellen. Je nach Belegung der Achsen erkennt man darin recht anschaulich das Abtastungsschema innerhalb des Streubereiches der Parameter.



Wichtig:
- Die Taylorreihen (als Ersatzfunktionen) der Moment-Methode und damit die Probabilistik können nur berechnet werden, wenn alle Stützstellen erfolgreich simuliert wurden (Status=Ok)! Bei den Sample-Methoden verringern "erfolglose" Simulationen nur die Größe der nutzbaren Stichprobe.
- Die Diode als numerisch kritisches Modell-Element kann hier zu Problemen führen, indem einzelne Simulationsläufe mit "Status=Failed" enden.
- Bekommt man dieses Problem mit der Diode nicht durch eine verbesserte Konfiguration der numerischen Integration in den Griff, muss man die Diode durch eine direkte Verbindung ersetzen!. Es entsteht dadurch jedoch ein geringer Parallelstrom zur Spule im eingeschalteten Zustand.
- Bei der Nutzung der Moment-Methode stehen Histogramme und Korrelationen nicht zur Verfügung (im Analyse-Menü inaktiv).
Streuungen
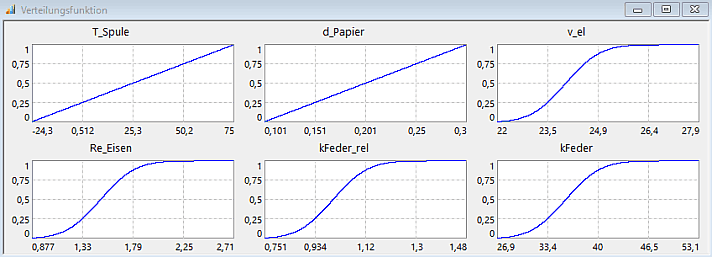
Analyse > Probabilistik > Verteilungsdichten > Entwurfsparameter > Streuungen zeigt für die gewählten Streuungen (ergänzt um die Hilfsrestriktionsgröße "kFeder") die "perfekten" Verteilungsdichtefunktionen:

- Die Fläche unter einer Verteilungsdichte-Funktion besitzt immer den Wert 1.
- Die Verteilungsdichte-Funktionen sind die Ableitungen der zugehörigen Verteilungsfunktionen nach ihrer Streugröße. Das erkennt man besonders deutlicher am Beispiel der gleichverteilten Spulentemperaturen und Papierdicken:

Restriktionsgrößen
Beachte: Für die "Hilfsgrößen" im Workflow (Ausgangsgrößen und Transfervariablen) werden keine Ersatzfunktionen approximiert. Deshalb erfolgt für diese Hilfsgrößen auch keine Probabilistik-Berechnung.
Die Verteilungsdichten der Ergebnisgrößen werden auf Grundlage der approximierten Taylorreihen 2. Ordnung und der darüber transformierten statistischen Momente der streuenden Eingangsgrößen für alle Restriktionen/Gütekriterien des Workflows berechnet:
- Bei den Restriktionsgrößen interessiert vor allem, in welchem Maße infolge der Streuungen unzulässige Werte auftreten:

- Im Beispiel wurden bei der Nennwert-Optimierung die maximale Abschaltspannung und der Maximalstrom ausgereizt. Das äußert sich in einer Teilversagenswahrscheinlichkeit von mehr als 50% für beide Restriktionsgrößen.
- Der Grenzwert von 40 K für die Drahterwärmung wird "praktisch" kaum überschritten.
- Hinweis: Leider kann man anhand der dargestellten Grenzwerte nur näherungsweise die tatsächlichen Grenzen der Streubereiche abschätzen. OptiY schneidet Werte der Dichtefunktion ab, die kleiner als 1/100 ihres Maximalwertes sind.
Dazu im Vergleich die Simulationsergebnisse des Latin-Hypercube-Sampling:

- Qualitativ und in Hinblick auf die Teilversagenswahrscheinlichkeiten stimmen die Ergebnisse recht gut überein.
- Im Unterschied zur Sampling-Methode wird bei der Momenten-Methode nicht die Gesamtversagenswahrscheinlichkeit in die Legende der Diagramme eingeblendet.
Versagenswahrscheinlichkeit
Die Teilversagenswahrscheinlichkeiten der einzelnen Restriktionen Fi können mit der Moment-Methode sehr genau berechnet werden, weil die Verteilungsdichten der Restriktionen bekannt sind. Aber die gesamte Systemversagenswahrscheinlichkeit F kann man damit nicht analytisch ermitteln:
- Es wird eine Hilfsgröße F berechnet, die sich aus den Teilversagenswahrscheinlichkeiten Fi mit den Gewichtsfaktoren wi der einzelnen Restriktionen summiert:

- Diese Hilfsgröße F wird als Maß für das Versagen im OptiY-Explorer als Bestandteil der Gütekriterien aufgelistet. Den Wert kann man sich z.B. in einem "Nennwert-Verlauf"-Fenster anzeigen lassen:

- Bei einem Versagen > 1 wird spätestens klar, dass dieser Wert F nur ein "Maß" für die Gesamtversagenswahrscheinlichkeit ist:
- Damit erhält man für die Minimierung der Versagenswahrscheinlichkeit mittels numerischer Optimierung ein stetiges und eindeutiges Maß für die vergleichende Bewertung von Lösungen.
- "Versagen=0" als Zielstellung einer Ausschuss-Minimierung bedeutend dann im Rahmen der Modellgenauigkeit "kein Ausschuss".
- Die Gewichtsfaktoren wi der Restriktionen lassen wir vorläufig unverändert auf dem Wert=1.
Sensitivitäten
Die Korrelationskoeffizienten stehen bei der Moment-Methode nicht als Ergebniswerte zur Verfügung. Auf Grundlage der Sensitivitäten kann man jedoch viel besser die Auswirkung der einzelnen Streuungen auf das Modellverhalten abschätzen.
Lokale Sensitivität
Auch für die Moment-Methode werden die lokalen Sensitivitäten als Schnittdiagramme bereitgestellt (Analyse > Antwortflächen > 1D Diagramm):
- Die Antwortflächen werden in diesem Falle durch die approximierten Taylorreihen 2. Ordnung gebildet.
- Im Unterschied zur Sample-Methode erfolgt die Gewinnung dieser Ersatzfunktion auf Grundlage einer systematischen Abtastung des Modells an einer minimalen Anzahl definierter Stützstellen:

- Hinweis: Anhand der Krümmungen der Schnittfunktionen insbesondere bei großen ΔY-Werten kann man schlussfolgern, dass die Wahl einer linearen Ersatzfunktion (First Order) wahrscheinlich eine unzulässige Vereinfachung darstellen würde.
Globale Sensitivitäten

Den Sensitivität-Charts kann man, wie vom Sampling-Experiment bereits bekannt, zwei wesentliche Informationen entnehmen:
- Welche Streuungen haben einen vernachlässigbaren Einfluss auf die betrachteten Bewertungsgrößen?
- Existieren merkliche Interaktionen zwischen den Streuungen?

Sind Haupt- und Totaleffekt wertmäßig ungefähr gleich, so kann man die Interaktionen zwischen den Streugrößen vernachlässigen:
- Damit entfallen die Modellberechnungen für die Gewinnung der Interaktionsinformationen.
- Für 5 Streugrößen reduziert sich damit der Berechnungsaufwand von 2n²+1=51 auf 2n+1=11 auf fast ein Fünftel!
Im Beispiel weichen die Werte für einige Haupt- und Totaleffekte insbesondere für den Maximalstrom und die Erwärmung merklich voneinander ab. Ob man dabei noch von "ungefähr gleich" sprechen kann, ist schwer zu entscheiden, solange man die Auswirkungen auf die Genauigkeit der probabilistischen Simulation nicht kennt:
- Man sollte in diesem Fall die Ergebnisse der probabilistischen Simulation mit und ohne Berücksichtigung der Interaktionen vergleichen.
- Nach erneuter Simulation (Interaktion=false) werden in den Sensitivitäts-Charts nur die Haupteffekte angezeigt:
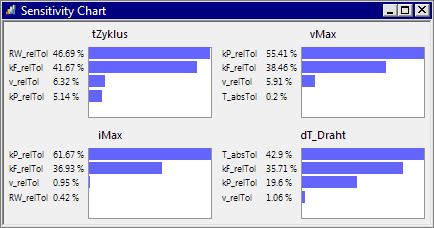

Kann man nach gründlicher Analyse der globalen Sensitivitäten z.B. 2 Streuungen vernachlässigen und aus dem Experiment-Workflow entfernen, so ergibt das eine weitere Verringerung des Berechnungsaufwandes auf 2n+1=7:
- Insbesondere in Vorbereitung einer geplanten probabilistischen Optimierung ist eine tiefgründige Analyse der Modelleigenschaften unbedingt erforderlich.
- Ausgehend von genaueren, aber auch zeitaufwändigeren Simulationen sollte man die "Stichproben-Simulation" soweit es geht "abrüsten", ohne dabei wesentlich an Genauigkeit einzubüßen.
Experiment-Ergebnisse
Für das eigene Nennwert-Optimum sind von den Teilnehmern der Lehrveranstaltung auf Grundlage der Simulation mittels Moment-Methode folgende Fragen als Bestandteil der einzusendenden Lösung zu beantworten:
- Welche drei streuungsbehafteten Parameter besitzen den größten Einfluss auf das Verhalten des Prägenadel-Antriebs? Die Entscheidung ist zu begründen!
- Wie ändern sich die Total-Effekte (vorher / nachher) von Feder-Streuung und Papier-Streuung auf die relevanten Bewertungsgrößen, wenn man die beiden Parameter-Streuungen mit dem geringsten Effekt vernachlässigt?
- Wirkung der Interaktionen → Zusätzlich sind für die auf 3 Streuungen reduzierte probabilistische Simulation vergleichend (vorher / nachher) folgende Werte der relevanten Bewertungsgrößen aufzulisten, wenn man die Interaktionen berücksichtigt bzw. vernachlässigt:
- Mittelwerte
- Maximal- und Minimalwerte anhand der Verteilungsdichte-Diagramme
- Teilversagenswahrscheinlichkeiten
- Ausschussquote: Wie groß ist für den Nennwert-optimierten Antrieb die "Gesamtversagenswahrscheinlichkeit [in %]" (Unter Berücksichtigung der Ergebnisse aus der Sample-Methode und Begründung der Wahl)?
Hinweise:
- Im Unterschied zur Sample-Methode haben die Einstellungen im virtuellen Entwurf keinerlei Einfluss auf die Ergebnisse der probabilistischen Simulation. Der virtuelle Entwurf wird in der Moment-Methode komplett ersetzt durch die analytische Berechnung der statistischen Momente der Ergebnis-Streuungen.
- Wir setzen vor den erforderlichen Experimenten in der realen Stichprobe der Versuchsplanung die Toleranz der zu vernachlässigenden Streuungen auf einen sehr kleinen Wert (auf 1/1000 der Original-Toleranz → für problemlose Rückänderung).
- Erforderlich ist danach jeweils eine komplette Neuberechnung nach dem Zurücksetzen der letzten Simulationsergebnisse.
Vorbereitung der Lösungseinsendung:
- Konfiguration des Experiments ohne reduzierte Streuungen unter Berücksichtigung der Interaktionen und den zugehörigen vollständig berechneten Ergebnissen.
- Der Workflow und alle Analyse-Fenster sind zu minimieren, mit Ausnahme der beiden zuletzt benutzten:
- Verteilungsdichten der relevanten Restriktionsgrößen
- Sensitivity Chart der relevanten Restriktionen