Software: FEM - Tutorial - Magnetfeld - Probabilistik - Kennfeld-Identifikation

Die Kraft- und Koppelfluss-Kennfelder eines E-Magneten kann man in Modellen zur System-Simulation als Ersatzmodell für eine konkrete Wandler-Geometrie benutzen:
- Die Ergebnisse einer FEM-Rastersuche kann man als Daten exportieren und die berechneten Abtaststellen des FEM-Modells als Stützstellen von 3D-Funktionsflächen in der System-Simulation verwenden. Aus diesen Stützstellen werden in der System-Simulation dann die Funktionswerte der Zwischenräume interpoliert.
- Die bei der probabilistischen Simulation vom FEM-Modellen generierten Antwortflächen kann man aber auch direkt als Modell-Code in Modelle der System-Simulation implementieren. Die Gewinnung von Ersatzmodellen nach diesem Prinzip wollen wir abschließend in diesem Übungskomplex durchführen.
Ausgehend vom Raster-Experiment Kennfeld-Berechnung konfigurieren wir nach dem Duplizieren ein Experiment Kennfeld-Identifikation.
Workflow
Wir werden die probabilistische Simulation benutzen, um über den gesamten Arbeitsbereich unseres E-Magneten die Antwortflächen für F(i,s) und Psi(i,s) bilden zu lassen:

- Die Nennwerte von Strom und Arbeitsluftspalt sind nun konstante Größen. Diese Streuungsmittenwerte sind so zu wählen, dass über den gesamten Streubereich numerisch instabile Werte nahe Null vermieden werden:
- i.Wert=5.01 A (i≥0.01 A)
- s.Wert=2.03 mm (s≥30 µm)
- Die Streuungen von Strom und Arbeitsluftspalt umfassen den gesamten Arbeitsbereich des E-Magneten:
- #i.Toleranz=10 A
- #s.Toleranz= 4 mm
- #i.Nennwert und #s.Nennwert Null (Streuungsmittenabstand=0)
- Die Gleichverteilung innerhalb der Streu-Bereiche gewährleistet eine gleichmäßige Abtastung, falls man eine Sample Methode verwendet.
Versuchsplanung
Wir werden das Experiment so konfigurieren, dass wir möglichst anschaulich erkennen, wie genau die approximierten Antwortflächen die wirklichen Übertragungsfunktionen des Modells abbilden:
- Grundlage für die Berechnung der Antwortfläche soll das Full Factorial Design sein, welches praktisch einer Rastersuche entspricht. Wir wählen dafür 6 Stufen, um die Anzahl der Modellberechnungen mit 37 gering zu halten. Die Anzahl 37 ergibt sich aus dem Raster 6x6 plus einer Stützstelle in der Mitte.
- Ein virtueller Stichprobenumfang=10000 zeigt uns im 3D-Anthill-Plot qualitativ die Lage der real berechneten Stichprobe in Bezug zur approximierten Antwortfläche.
Approximation mit Polynom-Ansatz
- Wir verwenden zuerst die bereits für die Sample Methode genutzte polynomiale Approximation und beginnen mit der Polynomordnung=1.
- Nach Abschluss der Simulation liegen die Antwortflächen als Funktionen im (i,s)-Raum vor.
- In die Diagramme der 3D-Antwortflächen blenden wir die Punkte der berechneten Stützstellen ein.
- Schrittweises Erhöhen der Polynomordnung mit anschließendem Neuberechnen der Antwortflächen
 führt zu einer optimalen Anpassung der Antwortflächen. Aus einem zu großem Wert für die Polynomordnung resultiert dann wieder eine Verschlechterung der Approximation, z.B. durch starke Welligkeit der fläche.
führt zu einer optimalen Anpassung der Antwortflächen. Aus einem zu großem Wert für die Polynomordnung resultiert dann wieder eine Verschlechterung der Approximation, z.B. durch starke Welligkeit der fläche.
Achtung: Ein Rücksetzen des Experiments mit erneuter Berechnung der realen Stichprobe ist dabei nicht erforderlich!

- Ein Drehen des 3D-Anthill-Plots zeigt deutlich die Lage der realen Modellwerte abseits der Antwortfläche. Besonders stark sind die Abweichungen bei der Kombination von minimalem Luftspalt mit minimalem Strom.
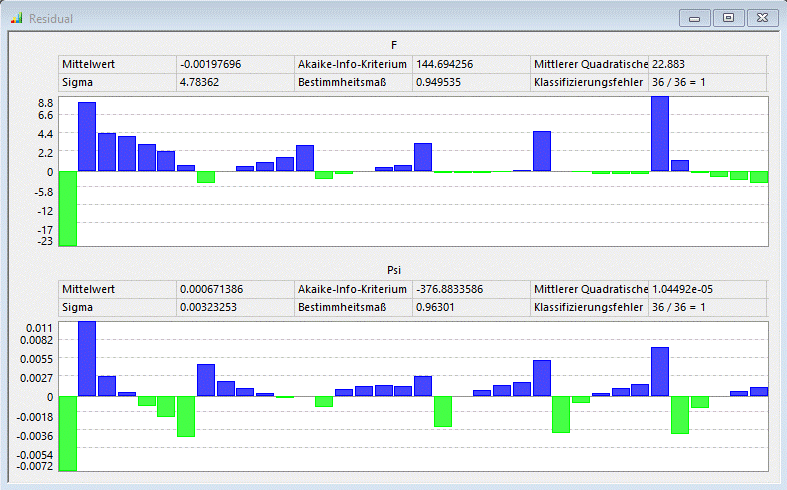
- Das Residuum-Plot zeigt quantitativ die Abbweichungen der realen Modellberechnungen von den identifizierten Antwortflächen. Bei der Magnetkraft liegt diese Abweichung überwiegend im Bereich von ca. 10%, was für ein Ersatzmodell häufig noch akzeptiert werden kann.
- Nicht akzeptabel ist jedoch, dass die Ersatzfunktion im Bereich kleiner Ströme zu negativen Kraftwerten führt, was physikalisch nicht korrekt ist!
- Ähnlich ungenau sehen die Ergebnisse für das Psi-Kennfeld aus:

Schlussfolgerung:
Polynom-Ansätze sind für die Bildung von globalen Ersatzmodellen bei nichtlinearem Übertragungsverhalten nicht besonders gut geeignet.
Approximation mit Gauss-Prozess
Der Gauss-Prozess, angewandt in der Geostatistik auch als Kriging bekannt, ist ein statistisches Verfahren, mit dem man Werte an Orten, für die keine Probe vorliegt, durch umliegende Messwerte interpolieren oder auch annähern kann.
Der Gauss Prozess besteht aus einem globalen Modell f(x) und einem stochastischen Prozess Z(x), welcher die mögliche Abweichung von dem globalen Modell beschreibt:

- x ist ein m-dimensionaler Parametervektor.
- Y(x) ist der Ergebnisvektor für den Punkt x im Parameterraum.
- f(x) sind Polynome beliebiger Ordnung, welche zusammen mit den unbekannten Regressionskoeffizienten βi die Regressionsfunktion bilden.
- Z(x) ist ein stationärer stochastischer Prozess mit dem Mittelwert Null, der Varianz σ und der Covarianz R. Dieser Anteil des Gauss Prozesses beschreibt das 95% Erwartungsintervall für jeden Punkt x des Parameterraumes.
In dem englischen Wikipedia-Artikel zum Kriging wird das für die Interpolation einer eindimensionale Funktion sehr anschaulich dargestellt:

Die berechneten Grenzverläufe des Erwartungsintervalls werden wesentlich bestimmt durch das Erfahrungswissen in Hinblick auf den erwartenden Verlauf der zu interpolierenden Funktion zwischen den bekannten Werten der Stichproben-Exemplare. Diese Erwartung wird durch die Wahl einer geeigneten Covarianz-Funktion R beschrieben.
- In OptiY sind unterschiedlichste Covarianz-Funktionen R iplementiert. Diese beschreiben den Verlauf des 95% Erwartungsintervalls zwischen den Stützstellen in Abhängigkeit von der Stützstellendichte. Die folgende Notation bezieht sich auf zwei Stützstellen x1 und x2 im Abstand (x1−x2):
- Square Exponential
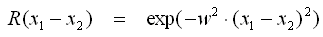
- Exponential
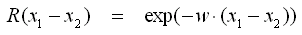
- Gamma-Exponential
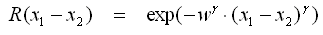
- Matern Class 3/2
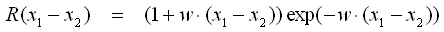
- Matern Class 5/2
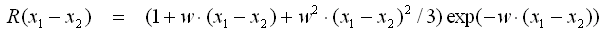
- Rational Quadratic
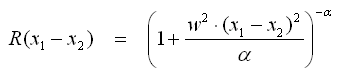

- Der allgemeine Fall für Exponential-Funktionen ist Gamma-Exponential, die anderen beiden Exponentialfunktionen sind die Spezialfälle für γ=1 bzw. γ=2.
- Die Matern Class Funktionen sind Erweiterungen der Exponential-Funktion.
- Die Hyper-Parameter w, γ and α werden mittels der Maximierung der Likelihood-Funktion der multivariaten Normalverteilung ermittelt.
Über die Polynomordnung des globalen Modells kann man einen Kompromiss finden zwischen bester Anpassung der interpolierten Regressionsfunktion an vorhandene Stützstellen und optimalem Verlauf zwischen diesen Stützstellen:
- Wie im vorherigen Abschnitt "Approximation mit Polynom-Ansatz" beschrieben, bestimmt die Polynomordnung des globalen Modells f(x) die allgemeine Richtung (globale Anpassung) der Regressionsfunktion. Die dabei verbleibenden Residuen sind noch sehr groß.
- Der stochastische Prozess Z(x) hat dann die Aufgabe, diese verbleibenden Residuen mittels der Covarianz-Funktion (Normal-Verteilung) zu eliminieren (lokale Anpassung).
- Wenn die Anzahl der Stützstellen bzw. der Daten hinreichend groß ist und man die verbleibenden Residuen statistisch auswertet, entsteht eine Normal-Verteilung (auch Gauss-Verteilung genannt) mit dem Mittelwert=0. Das ist die ursprüngliche Idee des Gauss-Prozesses.
- Wenn man die globale Anpassung mit einer zu hohen Ordnungen der Polynome durchführt, besitzt die Kurve mehr Freiheitsgrade als nötig. Das führt dann zu Welligkeiten zwischen den Stützstellen, weil dies durch keine Zwangsbedingungen verhindert wird.
Dieses Prinzip der Bildung von Ersatzmodellen (Antwortflächen) werden wir nun auf unser Kennfeld-Problem anwenden. Wir nutzen dafür das bereits konfigurierte Experiment Kennfeld-Identifikation ohne erneute Berechnung der Stichprobe:
- Wir wählen für die beiden Ergebnisgrößen F und Psi zur Approximation den Gauss Prozess und beginnen mit der kleinsten Polynomordnung=0. Als Covarianz-Funktion beginnen wir mit Exponential:


- Zusätzlich zu den Residuen und der 3D-Antwortfläche öffnen wir für jede Ergebnisgröße auch die Schnittdiagramm. Innerhalb der Schnittdiagramme aktivieren wir die Darstellung des Vertrauenintervalls.
- Nach dem Neuberechnen der Antwortflächen ergibt sich eine gute Approximation für beide Kennfelder: Die Approximation für das Psi-Kennfeld ist jedoch völlig unbrauchbar:
- Die Residuen zeigen, dass sämtliche Punkte der echten Stichprobe im Unterschied zur Polynom-Anpassung exakt (max. 2.5E-10) in die identifizierte Ersatzfunktionen F=f(s,i) bzw. Psi=f(s,i) eingebettet sind:

{kind=link}
{kind=link}
===> Achtung: der folgende Abschnitt ist noch nicht überarbeitet!!!
- Die Approximationsordnung sollte man nun schrittweise erhöhen, bis für alle Kriterien/Restriktionen die Residuen praktisch Null werden. Eine weitere Erhöhung der Approximationsordnung führt zwar zu noch kleineren Residuen-Werten, was aber keine Vorteile bringt. Infolge zu vieler Freiheitsgrade kann dies zu Welligkeiten zwischen den Stützstellen führen, welche nicht die realen physikalischen Abhängigkeiten widerspiegeln:
{kind=link}
{kind=link}
Frage:
Welche Approximationsordnung führt im Beispiel zu einem optimalen Ersatzmodell?
Nach dem Anzeigen der Schnittdiagramme für die Kraft und den Koppelfluss (Analyse - Antwortflächen - Schnittdiagramm), hat man die Möglichkeit, die 95% Vertrauensintervalle und die Stützstellen einzublenden:
{kind=link}
{kind=link}
{kind=link}
- Verändern der aktuellen Werte für den Strom und den Arbeitsluftspalt (z.B. durch Ziehen der roten Linie mit dem Cursor) führen je nach Position auf der Antwortfläche zu wesentlich veränderten Vertrauensintervallen.
- Befindet man sich mit den aktuellen Werten auf einem echten Stützpunkt innerhalb des Rasters, so sind die "Schläuche" der Vertrauensintervalle um alle Schnittfunktionen am schmalsten.
- An den Stützstellen selbst ist die Breite des Vertrauensintervalls immer Null, da der Wert bekannt ist.
Hinweise:
- Das berechnete Vertrauensintervall resultiert nur aus den benutzten mathematischen Ansätzen. Am Beispiel können wir dem interpolierten Kraftverlauf wesentlich stärker vertrauen! Wir wissen (im Unterschied zum mathematischen Formalismus), dass sich die Kraft zwischen den Stützstellen monoton ändert (ohne "Welligkeit").
- Die Vertrauensintervalle markieren den Worst Case der Unsicherheit bei fehlenden Kenntnissen zu den abgebildeten physikalischen Zusammenhängen.
Export des Ersatzmodells
Unabhängig davon, nach welchem Verfahren die Antwortflächen des Modells approximiert wurden, kann man die identifizierten mathematischen Funktionen als Programm-Code exportieren (Analyse - Antwortflächen - Modell Export):
- Zur Zeit kann in OptiY ein Quelltext als C-Code oder als m-Matlab erzeugt werden.
- Wir speichern unser Ersatzmodell als C-Code in die Datei Magnet_xx.c. (xx=Teilnehmer-Nummer in der Lehrveranstaltung).
- Dieser Quelltext enthält unter Benutzung der gewählten Covariance-Funktion die identifizierten Gauss-Ketten für alle Kriterien/Restriktionen (im Folgenden gekürzt):
float Covariance(float x1[],float x2[],float p[])
{
float Co, W;
W = 0;
for(int i = 0; i<2; i++) {
W = W + (x1[i]-x2[i])*(x1[i]-x2[i])*p[i]*p[i];
}
Co = exp(-W);
return Co;
}
float F(float #i, float #s)
{
float p[2];
float x1[2];
float x2[2];
float y = -46.7372056;
y = y+10.5264863*pow(#i,1);
y = y+4.62081477*pow(#s,1);
p[0] = 0.161298213;
p[1] = 0.928373134;
x1[0] = #i;
x1[1] = #s;
x2[0] = 5.01;
x2[1] = 2.02;
y = y-183.986679*Covariance(x1,x2,p);
x2[0] = 0.01;
x2[1] = 0.02;
y = y-8624.5598*Covariance(x1,x2,p);
x2[0] = 2.01;
x2[1] = 0.02;
y = y+27677.7263*Covariance(x1,x2,p);
:
:
x2[0] = 10.01;
x2[1] = 4.02;
y = y-1042.30105*Covariance(x1,x2,p);
return y;
}
float Psi(float #i, float #s)
{
float p[2];
float x1[2];
float x2[2];
float y = 0.0189621757;
y = y+0.00649675907*pow(#i,1);
y = y-0.00349272992*pow(#s,1);
p[0] = 0.590637256;
p[1] = 0.777378104;
x1[0] = #i;
x1[1] = #s;
x2[0] = 5.01;
x2[1] = 2.02;
y = y-0.000721074847*Covariance(x1,x2,p);
x2[0] = 0.01;
x2[1] = 0.02;
y = y-0.0269366063*Covariance(x1,x2,p);
x2[0] = 2.01;
x2[1] = 0.02;
y = y+0.0298939078*Covariance(x1,x2,p);
:
:
x2[0] = 10.01;
x2[1] = 4.02;
y = y-0.00522234634*Covariance(x1,x2,p);
return y;
}