Software: FEM - Tutorial - Magnetfeld - Probabilistik - Momenten-Methode: Unterschied zwischen den Versionen
KKeine Bearbeitungszusammenfassung |
KKeine Bearbeitungszusammenfassung |
||
| (10 dazwischenliegende Versionen von 2 Benutzern werden nicht angezeigt) | |||
| Zeile 4: | Zeile 4: | ||
[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_neues_streuexperiment.gif|right]] | [[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_neues_streuexperiment.gif|right]] | ||
Vergleichend zur Toleranzsimulation mit der Sampling-Methode Latin '''''Hypercube Sampling''''' soll nun der analytische Ansatz der '''''Moment-Methode''''' benutzt werden: | Vergleichend zur Toleranzsimulation mit der Sampling-Methode Latin '''''Hypercube Sampling''''' soll nun der analytische Ansatz der '''''Moment-Methode''''' benutzt werden: | ||
* Durch Duplizieren gewinnen wir aus dem Zufallszahlen-Experiment die Grundlage für die Konfiguration eines neuen Experiments. | * Durch Duplizieren gewinnen wir aus dem Zufallszahlen-Experiment die Grundlage für die Konfiguration eines neuen Experiments und wählen dieses als Startup-Experiment. | ||
* Auch für das neue Experiment vergeben wir einen sinnvollen Namen. | * Auch für das neue Experiment vergeben wir einen sinnvollen Namen. | ||
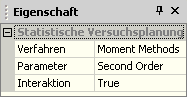
* In dem neuen Experiment müssen wir die Versuchsplanung entsprechend umkonfigurieren und die Darstellung von Ergebnissen neu organisieren. | * In dem neuen Experiment müssen wir die Versuchsplanung entsprechend umkonfigurieren und die Darstellung von Ergebnissen neu organisieren.<div align="center">[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_versuchsplanung_second_order.gif| ]]</div> | ||
=== Moment-Methode === | === Moment-Methode === | ||
Der erste Schritt der Moment-Methode verläuft ähnlich wie bei den Sampling-Methoden - es wird ein Ersatzmodell gebildet: | Der erste Schritt der Moment-Methode verläuft ähnlich wie bei den Sampling-Methoden - es wird ein Ersatzmodell gebildet: | ||
* Für jede Ergebnis-Größe (Gütekriterien und Restriktionen) des Workflows wird eine Funktion '''''f''''' gebildet, mit welcher sich der Wert der Ergebnis-Größe aus dem Variablenvektor '''''x''''' der '''n''' Streu-Größen berechnen lässt. | * Für jede Ergebnis-Größe (Gütekriterien und Restriktionen) des Workflows wird eine Funktion '''''f''''' gebildet, mit welcher sich der Wert der Ergebnis-Größe aus dem Variablenvektor '''''x''''' der '''n''' Streu-Größen berechnen lässt. | ||
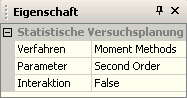
* Für die Approximation jeder dieser Funktionen '''''f''''' wird im Unterschied zur Sampling-Methode eine Taylor-Reihe benutzt. Ihre Approximationsordnung ist dabei auf den Maximalwert 2 beschränkt (''First Order=1'' / ''Second Order=2''). | * Für die Approximation jeder dieser Funktionen '''''f''''' wird im Unterschied zur Sampling-Methode eine Taylor-Reihe benutzt. Ihre Approximationsordnung ist dabei auf den Maximalwert 2 beschränkt (''First Order=1'' / ''Second Order=2''). | ||
* '''''Hinweis:''''' Bei Wahl der Momenten-Methode zur statistischen Versuchsplanung sind die Einstellungen der Gütekriterien in Hinblick auf die Approximation wirkungslos! | * '''''Hinweis:''''' Bei Wahl der Momenten-Methode zur statistischen Versuchsplanung sind die Einstellungen der Gütekriterien in Hinblick auf die Approximation wirkungslos! | ||
* Wir nutzen zuerst die '''''Second Order Analysis''''' (Ordnung=2) mit Berücksichtigung von Interaktionen (Wechselwirkungen) zwischen den Streu-Größen. Die vollständige Funktion dafür lautet: | * Wir nutzen zuerst die '''''Second Order Analysis''''' (Ordnung=2) mit Berücksichtigung von Interaktionen (Wechselwirkungen) zwischen den Streu-Größen. Die vollständige Funktion dafür lautet:<div align="center"> [[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_taylorreihe_komplett.gif| ]] </div> | ||
<div align="center"> [[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_taylorreihe_komplett.gif| ]] </div> | |||
Die erforderlichen Ersatz-Übertragungsfunktionen werden durch die Berechnung von Stützstellen gewonnen: | Die erforderlichen Ersatz-Übertragungsfunktionen werden durch die Berechnung von Stützstellen gewonnen: | ||
* Pro Streu-Größe '''S<sub>i</sub>''' werden nur drei Stützstellen genutzt (Grenzwerte und Mittelwert) | * Pro Streu-Größe '''S<sub>i</sub>''' werden nur drei Stützstellen genutzt (Grenzwerte und Mittelwert) | ||
| Zeile 24: | Zeile 19: | ||
Nach der Berechnung des Ersatz-Modells (Menge von Taylor-Reihen) erfolgt die eigentliche Analyse wieder auf Basis dieses Ersatz-Modells. Hier existiert nun der entscheidende Unterschied zu den Sampling Methoden: | Nach der Berechnung des Ersatz-Modells (Menge von Taylor-Reihen) erfolgt die eigentliche Analyse wieder auf Basis dieses Ersatz-Modells. Hier existiert nun der entscheidende Unterschied zu den Sampling Methoden: | ||
* Die statistischen [ | * Die statistischen [https://de.wikipedia.org/wiki/Moment_(Stochastik) ''Momente''] der Ausgangsgrößen werden analytisch näherungsweise aus den statistischen Momenten der Eingangsgrößen berechnet. Aus den berechneten Momenten werden anschließend die Verteilungen der Ausgangsgrößen approximiert. | ||
* Das Verfahren der ''Second Order Analysis'' arbeitet sehr genau, wenn das Verhalten der Ausgangsgrößen im Streu-Bereich höchstens quadratische Abhängigkeiten zu den Streu-Größen aufweist. Die Ergebnisse mit 4 Streu-Größen sind dann vergleichbar mit einer Monte-Carlo-Simulation bei einer Stichprobengröße von 100.000. Da das Verfahren ohne Zufallszahlen arbeitet, ist es numerisch sehr stabil und erlaubt auch eine schnelle Optimierung unter Berücksichtigung von Streuungen. | * Das Verfahren der ''Second Order Analysis'' arbeitet sehr genau, wenn das Verhalten der Ausgangsgrößen im Streu-Bereich höchstens quadratische Abhängigkeiten zu den Streu-Größen aufweist. Die Ergebnisse mit 4 Streu-Größen sind dann vergleichbar mit einer Monte-Carlo-Simulation bei einer Stichprobengröße von 100.000. Da das Verfahren ohne Zufallszahlen arbeitet, ist es numerisch sehr stabil und erlaubt auch eine schnelle Optimierung unter Berücksichtigung von Streuungen. | ||
* Der Nachteil der ''Second Order Analyse'' liegt in dem hohen Rechenaufwand bei einer großer Anzahl von Streu-Größen (Simulationsläufe = '''2·n<sup>2</sup>+1'''). | * Der Nachteil der ''Second Order Analyse'' liegt in dem hohen Rechenaufwand bei einer großer Anzahl von Streu-Größen (Simulationsläufe = '''2·n<sup>2</sup>+1'''). | ||
| Zeile 38: | Zeile 33: | ||
Die Genauigkeit des approximierten Modells an den Abtastpunkten kann man wie bei der Sampling-Methode über das Residual-Diagramm beurteilen ('''''Analyse > Antwortflächen > Residuum-Plot'''''):[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_residual_sec_order.gif|right]] | Die Genauigkeit des approximierten Modells an den Abtastpunkten kann man wie bei der Sampling-Methode über das Residual-Diagramm beurteilen ('''''Analyse > Antwortflächen > Residuum-Plot'''''):[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_residual_sec_order.gif|right]] | ||
* An zwei Abtaststellen ist die Abweichung im Beispiel um ca. den Faktor | * An zwei Abtaststellen ist die Abweichung im Beispiel um ca. den Faktor 4-5 höher, als die Maximalabweichung bei der Sampling-Methode. Da diese Abweichung des Ersatzmodells aber nur bei ca. 1% im Vergleich zur realen Modellberechnung liegt, kann man das akzeptieren. | ||
* '''''Achtung:''''' <br>Die Genauigkeit an den Abtaststellen der Moment-Methode sagt nichts über die Genauigkeit des Ersatz-Modells zwischen den Abtaststellen aus! Ob die gewählte Ordnung für die Taylor-Reihen ausreichend ist, kann man nur mit einer hinreichend großen Stichprobe in der Sampling-Methode überprüfen. | * '''''Achtung:''''' <br>Die Genauigkeit an den Abtaststellen der Moment-Methode sagt nichts über die Genauigkeit des Ersatz-Modells zwischen den Abtaststellen aus! Ob die gewählte Ordnung für die Taylor-Reihen ausreichend ist, kann man nur mit einer hinreichend großen Stichprobe in der Sampling-Methode überprüfen. | ||
Nun ist sicher interessant, ob man in Hinblick auf den Einfluss der Streuungen zum gleichen Ergebnis kommt, wie bei der Sampling-Methode: | Nun ist sicher interessant, ob man in Hinblick auf den Einfluss der Streuungen zum gleichen Ergebnis kommt, wie bei der Sampling-Methode: | ||
* Korrelationsmatrix und -tabelle stehen bei der Momenten-Methode nicht zur Verfügung. | * Korrelationsmatrix und -tabelle stehen bei der Momenten-Methode nicht zur Verfügung. | ||
* | * Sensitivität-Chart und -Tabelle zeigen den Effekt der Streuungen auf die Ausgangsgrößen:<div align="center"> [[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_sec_ord_sensitivities.gif| ]] </div> | ||
* Bis auf winzige Abweichungen erhält man die gleichen Ergebnisse, wie bei der Sampling-Methode.[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_sec_ord_ohne_interaktion.gif|right]] | * Bis auf winzige Abweichungen erhält man die gleichen Ergebnisse, wie bei der Sampling-Methode.[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_sec_ord_ohne_interaktion.gif|right]] | ||
Die praktische Gleichheit von Haupt- und Totaleffekt bedeutet, dass es keine Interaktionen (Wechselwirkungen) zwischen den Streugrößen gibt. Mit dieser Erkenntnis sollte man die Versuchsplanung entsprechend ändern:[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_sec_ord_reduziert.gif|right]] | Die praktische Gleichheit von Haupt- und Totaleffekt bedeutet, dass es keine Interaktionen (Wechselwirkungen) zwischen den Streugrößen gibt. Mit dieser Erkenntnis sollte man die Versuchsplanung entsprechend ändern:[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_sec_ord_reduziert.gif|right]] | ||
* Die Auswirkung auf Berechnungszeit einer Stichprobe ist enorm, da der Großteil der Abtastschritte für die Berücksichtigung der Interaktionen benötigt wird. Die benötigte Anzahl der Modell-Läufe steigt nun nur noch linear mit der Anzahl der Streu-Größen '''n''' (Simulationsläufe = '''2·n+1'''). | * Die Auswirkung auf die Berechnungszeit einer Stichprobe ist enorm, da der Großteil der Abtastschritte für die Berücksichtigung der Interaktionen benötigt wird. Die benötigte Anzahl der Modell-Läufe steigt nun nur noch linear mit der Anzahl der Streu-Größen '''n''' (Simulationsläufe = '''2·n+1'''). | ||
* Im Beispiel verringert sich die erforderliche Zahl von Modellrechnungen von '''19''' auf '''7''', was man im 3D-Anthill-Plot gut beobachten kann. | * Im Beispiel verringert sich die erforderliche Zahl von Modellrechnungen von '''19''' auf '''7''', was man im 3D-Anthill-Plot gut beobachten kann. | ||
* Die mit dieser "reduzierten" Second-Order-Methode erzielten Ergebnisse sind im Beispiel praktisch identisch, da es keine Wechselwirkungen zwischen den Streu-Größen gibt. | * Die mit dieser "reduzierten" Second-Order-Methode erzielten Ergebnisse sind im Beispiel praktisch identisch, da es keine Wechselwirkungen zwischen den Streu-Größen gibt.[[Bild:Software_FEM_-_Tutorial_-_Magnetfeld_-_optiy_first_ord_3d_anthill.gif|right]] | ||
'''''Hinweis:''''' | '''''Hinweis:''''' Die First-Order-Approximation ohne Interaktion erfordert nur '''n+1''' Modellabtastungen. Allerdings werden damit nur Hyperebenen (ohne Krümmung) zwischen den abgetasteten Ecken des Streu-Raumes interpoliert: | ||
* Das ist im Beispiel zwar nicht ganz exakt, aber die damit ermittelten Ergebnisse sind nicht wesentlich andere. | |||
Das ist im Beispiel zwar nicht ganz exakt, aber die damit ermittelten Ergebnisse sind nicht wesentlich andere. Besitzt man nur ein FEM-Modell mit sehr langen Berechnungszeiten, so sollte man in diesem Fall die Stichproben-Simulation innerhalb von Optimierungsexperimenten mit diesem First-Order-Ansatz durchführen! | * Besitzt man nur ein FEM-Modell mit sehr langen Berechnungszeiten, so sollte man in diesem Fall die Stichproben-Simulation innerhalb von Optimierungsexperimenten mit diesem First-Order-Ansatz durchführen!<div align="center"> [[Software:_FEM_-_Tutorial_-_Magnetfeld_-_Probabilistik_-_Monte-Carlo|←]] [[Software:_FEM_-_Tutorial_-_Magnetfeld_-_Probabilistik_-_Kennfeld-Identifikation|→]] </div> | ||
<div align="center"> [[Software:_FEM_-_Tutorial_-_Magnetfeld_-_Probabilistik_-_Monte-Carlo|←]] [[Software:_FEM_-_Tutorial_-_Magnetfeld_-_Probabilistik_-_Kennfeld-Identifikation|→]] </div> | |||
Aktuelle Version vom 23. Mai 2019, 12:07 Uhr

Vergleichend zur Toleranzsimulation mit der Sampling-Methode Latin Hypercube Sampling soll nun der analytische Ansatz der Moment-Methode benutzt werden:
- Durch Duplizieren gewinnen wir aus dem Zufallszahlen-Experiment die Grundlage für die Konfiguration eines neuen Experiments und wählen dieses als Startup-Experiment.
- Auch für das neue Experiment vergeben wir einen sinnvollen Namen.
- In dem neuen Experiment müssen wir die Versuchsplanung entsprechend umkonfigurieren und die Darstellung von Ergebnissen neu organisieren.

Moment-Methode
Der erste Schritt der Moment-Methode verläuft ähnlich wie bei den Sampling-Methoden - es wird ein Ersatzmodell gebildet:
- Für jede Ergebnis-Größe (Gütekriterien und Restriktionen) des Workflows wird eine Funktion f gebildet, mit welcher sich der Wert der Ergebnis-Größe aus dem Variablenvektor x der n Streu-Größen berechnen lässt.
- Für die Approximation jeder dieser Funktionen f wird im Unterschied zur Sampling-Methode eine Taylor-Reihe benutzt. Ihre Approximationsordnung ist dabei auf den Maximalwert 2 beschränkt (First Order=1 / Second Order=2).
- Hinweis: Bei Wahl der Momenten-Methode zur statistischen Versuchsplanung sind die Einstellungen der Gütekriterien in Hinblick auf die Approximation wirkungslos!
- Wir nutzen zuerst die Second Order Analysis (Ordnung=2) mit Berücksichtigung von Interaktionen (Wechselwirkungen) zwischen den Streu-Größen. Die vollständige Funktion dafür lautet:
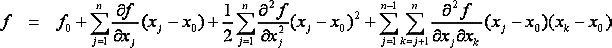
Die erforderlichen Ersatz-Übertragungsfunktionen werden durch die Berechnung von Stützstellen gewonnen:
- Pro Streu-Größe Si werden nur drei Stützstellen genutzt (Grenzwerte und Mittelwert)
- Bedingt durch die kombinatorische Abtastung des Modells steigt die benötigte Anzahl der Modell-Läufe quadratisch mit der Anzahl der Streu-Größen n (Simulationsläufe = 2·n2+1).
- Diese Art der Gewinnung eines Ersatz-Modells führt nur zu einem hinreichend genauen Ergebnis, wenn für das zu approximierende reale Modellverhalten Taylor-Reihen 2. Ordnung ausreichend sind. Zum Glück ist dies für die Mehrzahl der Anwendungsfälle zutreffend.
Nach der Berechnung des Ersatz-Modells (Menge von Taylor-Reihen) erfolgt die eigentliche Analyse wieder auf Basis dieses Ersatz-Modells. Hier existiert nun der entscheidende Unterschied zu den Sampling Methoden:
- Die statistischen Momente der Ausgangsgrößen werden analytisch näherungsweise aus den statistischen Momenten der Eingangsgrößen berechnet. Aus den berechneten Momenten werden anschließend die Verteilungen der Ausgangsgrößen approximiert.
- Das Verfahren der Second Order Analysis arbeitet sehr genau, wenn das Verhalten der Ausgangsgrößen im Streu-Bereich höchstens quadratische Abhängigkeiten zu den Streu-Größen aufweist. Die Ergebnisse mit 4 Streu-Größen sind dann vergleichbar mit einer Monte-Carlo-Simulation bei einer Stichprobengröße von 100.000. Da das Verfahren ohne Zufallszahlen arbeitet, ist es numerisch sehr stabil und erlaubt auch eine schnelle Optimierung unter Berücksichtigung von Streuungen.
- Der Nachteil der Second Order Analyse liegt in dem hohen Rechenaufwand bei einer großer Anzahl von Streu-Größen (Simulationsläufe = 2·n2+1).
Analyse
- Nach Start der Simulation erfolgen zuerst die Modellrechnungen für die Gewinnung des Ersatz-Modells. Erst danach werden die Verteilungen der Ausgangsgrößen berechnet. Die Ergebnisse der Probabilistik stehen also erst nach allen Modellberechnungen zur Verfügung.
- Man kann dies sehr gut beobachten, indem man vor dem Start der Simulation zusätzlich zu den Verteilungsdichten der Streuungen auch die 2D-Anthill-Plots F(sAnker_), F(sGleit_) und F(sDeckel_) öffnet:
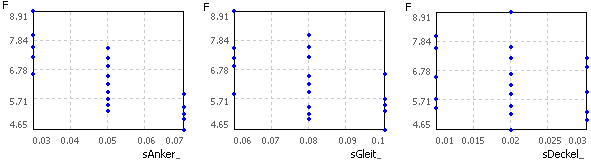
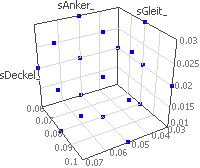


Während der 19 Abtastberechnungen werden schrittweise die Punkte in den Anthill-Plots abgebildet. Anhand der senkrechten Linien erkennt man deutlich die Abtastungen in der Mitte und an den Rändern jeder Streu-Größe.
Damit wird der gesamte Streu-Raum sehr gleichmäßig abgetastet, wie man sehr gut im 3D-Anthill-Plot erkennt.
Erst nach der kompletten Abtastung erscheinen die Verteilungen:

Hinweis: Histogramme stehen bei der Moment-Methode nicht zur Verfügung!
Die Genauigkeit des approximierten Modells an den Abtastpunkten kann man wie bei der Sampling-Methode über das Residual-Diagramm beurteilen (Analyse > Antwortflächen > Residuum-Plot):

- An zwei Abtaststellen ist die Abweichung im Beispiel um ca. den Faktor 4-5 höher, als die Maximalabweichung bei der Sampling-Methode. Da diese Abweichung des Ersatzmodells aber nur bei ca. 1% im Vergleich zur realen Modellberechnung liegt, kann man das akzeptieren.
- Achtung:
Die Genauigkeit an den Abtaststellen der Moment-Methode sagt nichts über die Genauigkeit des Ersatz-Modells zwischen den Abtaststellen aus! Ob die gewählte Ordnung für die Taylor-Reihen ausreichend ist, kann man nur mit einer hinreichend großen Stichprobe in der Sampling-Methode überprüfen.
Nun ist sicher interessant, ob man in Hinblick auf den Einfluss der Streuungen zum gleichen Ergebnis kommt, wie bei der Sampling-Methode:
- Korrelationsmatrix und -tabelle stehen bei der Momenten-Methode nicht zur Verfügung.
- Sensitivität-Chart und -Tabelle zeigen den Effekt der Streuungen auf die Ausgangsgrößen:
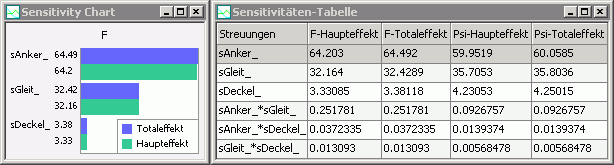
- Bis auf winzige Abweichungen erhält man die gleichen Ergebnisse, wie bei der Sampling-Methode.


Die praktische Gleichheit von Haupt- und Totaleffekt bedeutet, dass es keine Interaktionen (Wechselwirkungen) zwischen den Streugrößen gibt. Mit dieser Erkenntnis sollte man die Versuchsplanung entsprechend ändern:

- Die Auswirkung auf die Berechnungszeit einer Stichprobe ist enorm, da der Großteil der Abtastschritte für die Berücksichtigung der Interaktionen benötigt wird. Die benötigte Anzahl der Modell-Läufe steigt nun nur noch linear mit der Anzahl der Streu-Größen n (Simulationsläufe = 2·n+1).
- Im Beispiel verringert sich die erforderliche Zahl von Modellrechnungen von 19 auf 7, was man im 3D-Anthill-Plot gut beobachten kann.
- Die mit dieser "reduzierten" Second-Order-Methode erzielten Ergebnisse sind im Beispiel praktisch identisch, da es keine Wechselwirkungen zwischen den Streu-Größen gibt.

Hinweis: Die First-Order-Approximation ohne Interaktion erfordert nur n+1 Modellabtastungen. Allerdings werden damit nur Hyperebenen (ohne Krümmung) zwischen den abgetasteten Ecken des Streu-Raumes interpoliert:
- Das ist im Beispiel zwar nicht ganz exakt, aber die damit ermittelten Ergebnisse sind nicht wesentlich andere.
- Besitzt man nur ein FEM-Modell mit sehr langen Berechnungszeiten, so sollte man in diesem Fall die Stichproben-Simulation innerhalb von Optimierungsexperimenten mit diesem First-Order-Ansatz durchführen!